Word Embedding Explained: Key Concepts and Techniques


Table of contents
- Introduction
- Word Embeddings
- One Hot Encoding
- Example
- Limitations of One-Hot Encoding
- TF-IDF (Term Frequency-Inverse Document Frequency)
- Example Dataset
- Step 1: Compute TF (Term Frequency)
- Step 2: Compute IDF (Inverse Document Frequency)
- Step 3: Compute TF-IDF
- Key Insights
- Limitations of TF-IDF
- Word2Vec
- How Word2Vec Works
- Explanation
- Improvements & Customizations
- Why is Word2Vec Important?
- Limitations of Word2Vec
- Pre-trained word embedding model
Introduction
Have you ever wondered how machines understand human language? How does Google suggest search queries even before you finish typing? How do chatbots comprehend user queries and generate relevant responses? The secret lies in word embeddings—a powerful technique that enables machines to represent words as numerical vectors, capturing their meanings and relationships in a high-dimensional space.
Word Embeddings
Word embedding techniques are used to represent words mathematically. One Hot Encoding, TF-IDF, Word2Vec, and FastText are commonly used word embedding methods. One or more of these techniques are chosen based on the data's condition, size, and processing purpose.
In traditional NLP approaches, words were represented using techniques like one-hot encoding, which assigned each word a unique vector. However, this method had major limitations: it resulted in high-dimensional, sparse representations and failed to capture semantic relationships between words. Word embeddings revolutionized NLP by providing dense vector representations where similar words have similar vector representations based on their context.
One Hot Encoding
One of the most basic techniques used to represent data numerically is the One Hot Encoding technique. In this method, a vector is created in the size of the total number of unique words. The value of vectors is assigned such that the value of each word belonging to its index is 1 and the others are 0. As an example
Example

Applying One-Hot Encoding results in a sparse matrix where each word is assigned a unique position. The problem with this approach is that it does not capture relationships between words, making it inefficient for tasks that require semantic understanding.
Limitations of One-Hot Encoding
High Dimensionality: As the vocabulary size grows, the vector representation becomes extremely large.
No Semantic Meaning: Words that are similar in meaning (مثل: "ممتاز" و "كويس") have no relationship in the encoded space.
Sparse Representation: Most values in the vector are
0, leading to inefficient storage and computation.
TF-IDF (Term Frequency-Inverse Document Frequency)
TF-IDF is a statistical measure used to determine the mathematical significance of words in documents. Unlike One-Hot Encoding, which only represents word presence, and word embeddings, which capture semantics, TF-IDF balances word importance by considering how frequently a term appears in a document relative to its occurrence in a larger corpus.
How TF-IDF Works
TF-IDF is calculated as follows:
$$TF(t, d) = \frac{\text{No. of times term } t \text{ appears in docx } d}{\text{Total No. of terms in docx } d}$$
$$IDF(t) = \log \left( \frac{\text{Total No. of docx}}{\text{Total No. of docx containing term } t} \right)$$
$$TF-IDF(t, d) = TF(t, d) \times IDF(t)$$
TF (Term Frequency): Measures how often a word appears in a document.
IDF (Inverse Document Frequency): Reduces the weight of common words (like "في" or "من") and gives higher importance to rare words.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
# Sample Data
data = {
"ID": [1, 2, 3, 4, 5],
"comment": [
"الخدمة كانت ممتازة جدًا",
"المكان وحش والخدمة بطيئة",
"الأكل حلو بس الخدمة عادية",
"الخدمة كانت كويسة جدًا",
"مش عاجبني أسلوب الجرسون"
]
}
df = pd.DataFrame(data)
# Initialize TF-IDF Vectorizer
vectorizer = TfidfVectorizer()
# Transform the text data
tfidf_matrix = vectorizer.fit_transform(df["comment"])
# Get feature names
feature_names = vectorizer.get_feature_names_out()
# Convert to DataFrame for better visualization
tfidf_df = pd.DataFrame(tfidf_matrix.toarray(), columns=feature_names)
pd.concat([df, tfidf_df], axis=1)
| ID | comment | أسلوب | الأكل | الجرسون | الخدمة | المكان | بس | بطيئة | جد | حلو | عاجبني | عادية | كانت | كويسة | مش | ممتازة | والخدمة | وحش | |
| 0 | 1 | الخدمة كانت ممتازة جدًا | 0.0 | 0.000000 | 0.0 | 0.403826 | 0.0 | 0.000000 | 0.0 | 0.486484 | 0.000000 | 0.0 | 0.000000 | 0.486484 | 0.000000 | 0.0 | 0.602985 | 0.0 | 0.0 |
| 1 | 2 | المكان وحش والخدمة بطيئة | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.5 | 0.000000 | 0.5 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.5 | 0.5 |
| 2 | 3 | الأكل حلو بس الخدمة عادية | 0.0 | 0.474125 | 0.0 | 0.317527 | 0.0 | 0.474125 | 0.0 | 0.000000 | 0.474125 | 0.0 | 0.474125 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.0 |
| 3 | 4 | الخدمة كانت كويسة جدًا | 0.0 | 0.000000 | 0.0 | 0.403826 | 0.0 | 0.000000 | 0.0 | 0.486484 | 0.000000 | 0.0 | 0.000000 | 0.486484 | 0.602985 | 0.0 | 0.000000 | 0.0 | 0.0 |
| 4 | 5 | مش عاجبني أسلوب الجرسون | 0.5 | 0.000000 | 0.5 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.5 | 0.000000 | 0.000000 | 0.000000 | 0.5 | 0.000000 | 0.0 | 0.0 |
Example Dataset
| ID | التعليق |
| 1 | الخدمة كانت ممتازة جدًا |
| 2 | المكان وحش والخدمة بطيئة |
| 3 | الأكل حلو بس الخدمة عادية |
We will calculate the TF-IDF score for the word "الخدمة".
Step 1: Compute TF (Term Frequency)
TF is calculated for each document:
| ID | التعليق | الخدمه TF |
| 1 | الخدمة كانت ممتازة جدًا | 1/4=0.25 |
| 2 | المكان وحش والخدمة بطيئة | 1/4=0.25 |
| 3 | الأكل حلو بس الخدمة عادية | 1/5=0.20 |
Step 2: Compute IDF (Inverse Document Frequency)
First, count how many documents contain the word "الخدمة":
- It appears in 3 out of 3 documents.
$$IDF=log( 3/ 3 )=log(1)=0$$
Since the word appears in every document, its IDF is 0, making its TF-IDF score = 0 in all documents.
Step 3: Compute TF-IDF
$$TF-IDF=TF×IDF=(TF×0)=0$$
So, "الخدمة" is not useful for distinguishing between comments because it appears in all of them.
Key Insights
If a word appears in every document, its IDF becomes 0, meaning it has no importance.
Rare words have higher IDF values, making them more important.
Limitations of TF-IDF
No Context Awareness: It treats words independently, meaning they are unrelated, even though they mean similar things.
Sparse Representation: TF-IDF still creates high-dimensional vectors, which may be inefficient.
Morphological Complexity: Arabic words vary in form (خدمة, خدمات, خدم) but have related meanings. TF-IDF does not automatically account for this.
Word2Vec
Word2vec is a commonly used technique for word embeddings. It scans the entire corpus and creates vectors by analyzing the frequency of co-occurrence with the target word. This process also uncovers the semantic proximity of related words. For instance, if we let each letter in the sequences ..x y A z w.., ..x y B z k.., and ..x l C d m.. represent different words, then word_A will be closer to word_B than to word_C. Accounting for this relationship during vector formation mathematically expresses the semantic closeness between words.
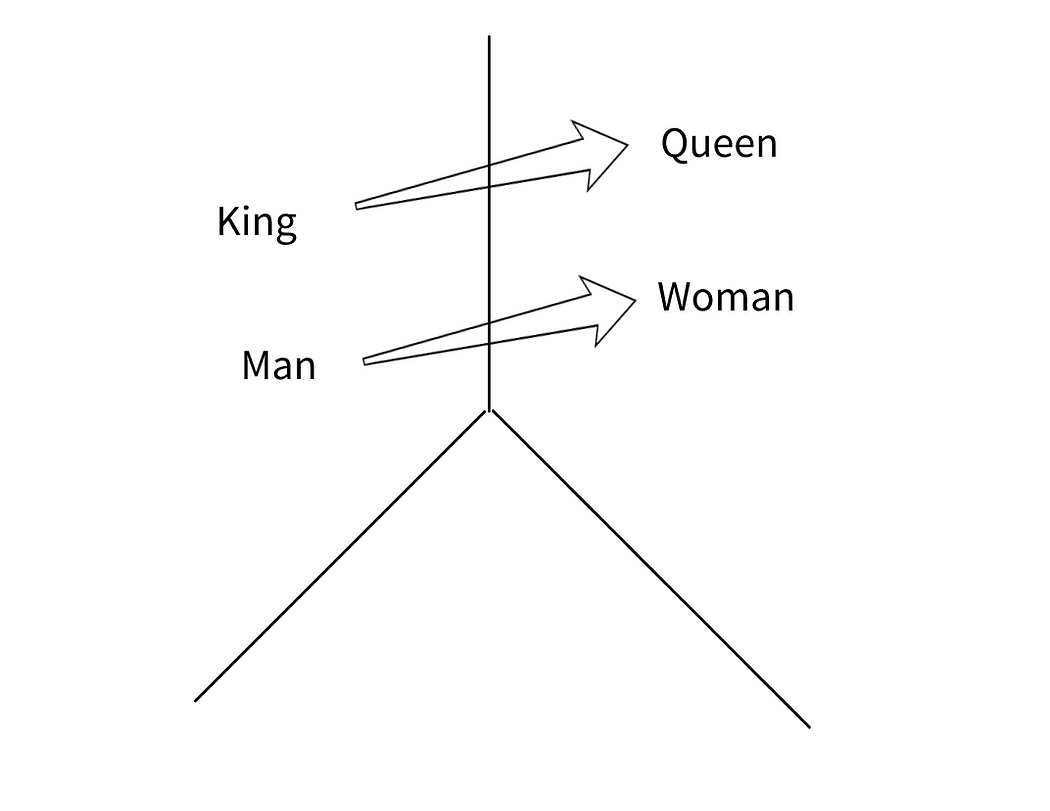
Figure shows one of the most frequently used images in Word2Vec. The semantic closeness between these words is the mathematical closeness of the vector values to each other. One of the frequently given examples is the equation
$$\text{King} - \text{Man} + \text{Woman}\approx \text{Queen}$$
What happens here is that the vector value obtained as a result of subtracting and adding the vectors from each other is equal to the vector corresponding to the “queen” expression. It can be understood that the words “king” and “queen” are very similar to each other, but vectorial differences arise only because of their gender.
How Word2Vec Works
Instead of treating words as isolated entities (like TF-IDF), Word2Vec scans an entire corpus and learns word representations by predicting surrounding words (CBOW) or predicting a target word based on context words (Skip-Gram).
CBOW (Continuous Bag of Words): Predict center word from context words.
Skip-Gram (SG): Predict context words based on center words.
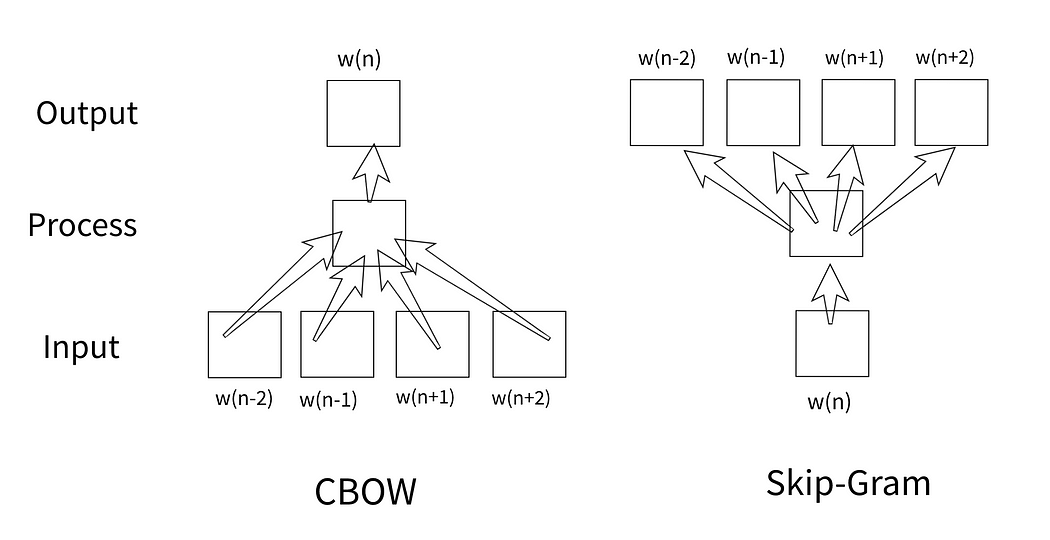
Skip-grams with Negative Sampling (SGNS): same as SG, but predict if the Context and Center words are actually valid together
Center → Word to have vector for
Context → Surrounding Window

def get_w2vdf(df):
w2v_df = pd.DataFrame(df["sentences"]).values.tolist()
for i in range(len(w2v_df)):
w2v_df[i] = w2v_df[i][0].split(" ")
return w2v_df
📌 Purpose: Converts a Pandas DataFrame column into a list of tokenized sentences.
📌 Steps:
Extracts the
"sentences"column as a list of values.Splits each sentence into words (tokenization).
Returns the processed list.
import gensim
from gensim.models import Word2Vec
def train_w2v(w2v_df):
cores = multiprocessing.cpu_count()
w2v_model = Word2Vec(min_count=4,
window=4,
size=300,
alpha=0.03,
min_alpha=0.0007,
sg=1,
workers=cores-1)
w2v_model.build_vocab(w2v_df, progress_per=10000)
w2v_model.train(w2v_df, total_examples=w2v_model.corpus_count, epochs=100, report_delay=1)
return w2v_model
Explanation
📌 Purpose: Trains a Word2Vec model using Skip-gram (
sg=1).
📌 Hyperparameters:min_count=4→ Ignores words appearing less than 4 times.window=4→ Considers 4 words before & after the target word.size=300→ Embedding size (vector dimension).alpha=0.03→ Initial learning rate.min_alpha=0.0007→ Minimum learning rate (reduces over time).sg=1→ Uses Skip-gram (setsg=0for CBOW).workers=cores-1→ Uses all CPU cores except one for training.
w2v_df = get_w2vdf(df)
w2v_model = train_w2v(w2v_df)
# Get Word Embedding (Vector)
vector = w2v_model.wv["برمجة"]
print(vector) # 300-dimensional vector
#Find Similar Words
similar_words = w2v_model.wv.most_similar("كلب", topn=5)
print(similar_words)
# Word Analogy (King - Man + Woman = Queen)
analogy = w2v_model.wv.most_similar(positive=["ملك", "امرأة"], negative=["رجل"], topn=1)
print(analogy) # Finds the closest match (likely "ملكة").
Improvements & Customizations
Train on larger datasets for better embeddings.
Experiment with CBOW (
sg=0) for comparison.Fine-tune
min_count,size,window, etc.
Why is Word2Vec Important?
Captures word relationships: Unlike TF-IDF, it understands similarities between words (e.g., "king" and "queen" are close).
Dimensionality reduction: Instead of large sparse matrices (TF-IDF), it generates low-dimensional dense vectors.
Handles polysemy better than TF-IDF: The meaning of "bank" (finance vs. riverbank) can be inferred from the surrounding words.
Limitations of Word2Vec
Context Independence: Word2Vec assigns one vector per word, meaning polysemous words like "bank" have a single representation, even if they have multiple meanings.
Fails on Out-of-Vocabulary (OOV) Words: If a word wasn’t in training data, Word2Vec cannot generate its embedding.
Doesn’t Understand Word Order: Unlike BERT, Word2Vec doesn’t model sentence structure well.
Pre-trained word embedding model
GloVe (Global Vectors for Word Representation)
GloVe (Global Vectors) is a word embedding technique that learns word relationships from a co-occurrence matrix instead of a neural network like Word2Vec. It was developed by researchers at Stanford University.
How Does GloVe Work?
Unlike Word2Vec, which relies on local context windows, GloVe builds a word-word co-occurrence matrix from a large corpus and applies matrix factorization to learn word vectors.
Key Steps:
Build a Co-occurrence Matrix:
Count how often word wiw_iwi appears near word wjw_jwj.
The matrix captures the global statistics of the corpus.
Apply Matrix Factorization:
Use techniques like Singular Value Decomposition (SVD) to reduce dimensions.
This ensures words with similar distributional patterns have similar vectors.
Optimize with a Cost Function:
- Unlike Word2Vec, GloVe uses a logarithmic weighting function to give more importance to frequent word pairs.
wget http://nlp.stanford.edu/data/glove.6B.zip
unzip glove.6B.zip
📌 Files available:
glove.6B.50d.txt(50D embeddings)glove.6B.100d.txt(100D embeddings)glove.6B.300d.txt(300D embeddings)
For Arabic word Embedding, you can check : GloVe-Arabic\
Limitations of GloVe
Doesn't handle misspellings well → If a word isn’t in the training corpus, GloVe won’t have a vector for it.
Static embeddings → Unlike Word2Vec, it doesn’t consider context (e.g., "bank" as a financial institution vs. a riverbank).
Requires a large corpus → Needs a huge dataset to create meaningful co-occurrence matrices.
Not great for Arabic morphology → Arabic words change forms based on prefixes/suffixes, which GloVe doesn't handle well.
GloVe vs. Word2Vec
| Feature | GloVe | Word2Vec |
| Learning Approach | Co-occurrence Matrix | Neural Network (CBOW/Skip-gram) |
| Captures | Global word relationships | Local context-based word similarity |
| Performance | Strong on analogy tasks | Stronger in real-time applications |
| Training Time | Faster for large corpora | Slower due to iterative training |
FastText
FastText, developed by Facebook AI, is an advanced word embedding technique similar to Word2Vec but with a key difference:
It breaks words into subwords (N-grams) before training.
"مدرسة" → ["مدر", "درس", "رسة"]
This makes it very effective for languages with rich morphology like Arabic, where words often have prefixes, suffixes, and variations.
Why is FastText Good for Arabic?
🔹 Works well with different word forms
🔹 Handles typos and OCR errors
🔹 Improves text classification & search accuracy
🔹 Useful for Named Entity Recognition (NER)
import fasttext
# Download pre-trained Arabic model from Facebook
!wget https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ar.300.bin.gz
!gunzip cc.ar.300.bin.gz
# Load model
ft_model = fasttext.load_model("cc.ar.300.bin")
# Get vector for an Arabic word
vector = ft_model.get_word_vector("مدرسة") # Arabic word for "school"
print(vector[:10]) # Print first 10 values of the vector
Conclusion
FastText is one of the best choices for Arabic NLP because it can handle rich morphology, word variations, and spelling errors.
GloVe vs. Word2Vec vs. FastText
| Feature | Word2Vec | GloVe | FastText |
| Training Type | Predicts words from context | Co-occurrence matrix | Subword-based |
| Handles Misspellings | ❌ No | ❌ No | ✅ Yes |
| Captures Word Morphology | ❌ No | ❌ No | ✅ Yes |
| Good for Arabic? | ⚠️ Limited | ⚠️ Limited | ✅ Excellent |
| Pre-trained Models Available? | ✅ Yes | ✅ Yes | ✅ Yes |
| Works with Out-of-Vocab Words? | ❌ No | ❌ No | ✅ Yes |
AraVec
AraVec is a pretrained word embedding model for Arabic. It provides word vectors trained on large Arabic corpora, making it better suited for Arabic NLP tasks than general models like Word2Vec, GloVe, or FastText.
Why Use AraVec?
✅ Trained on Large Arabic Corpora → Wikipedia, Tweets, and other Arabic sources.
✅ Handles Arabic Morphology → Arabic has rich word variations due to prefixes/suffixes.
✅ Supports Word2Vec & FastText → Includes both CBOW & Skip-gram models.
✅ Pretrained Vectors Available → No need to train from scratch!
✅ ENG: Abu Bakr Soliman
How to Use AraVec in Python
1️⃣ Install Required Libraries
pip install gensim
3️⃣ Load AraVec Model
from gensim.models import KeyedVectors
embedding_path = "Embeddings/cc.ar.300.vec"
aravec_model = KeyedVectors.load_word2vec_format(embedding_path, binary=False)
4️⃣ Get Word Vector for an Arabic Word
word = "قهوة" # Arabic word for "coffee"
if word in aravec_model.wv:
print(aravec_model.wv[word]) # Prints the vector representation of "قهوة"
else:
print("Word not found in vocabulary")
5️⃣ Find Similar Words in Arabic
similar_words = aravec_model.wv.most_similar("قهوة", topn=5)
for word, similarity in similar_words:
print(f"{word}: {similarity}")
Expected Output:
makefileCopyEditشاي: 0.85
حليب: 0.82
مشروب: 0.79
مطعم: 0.75
فطور: 0.72
Conclusion
Word embeddings have significantly advanced Arabic Natural Language Processing (NLP), enabling machines to better grasp the nuances of the language. From improving machine translation to enhancing chatbot interactions, sentiment analysis, and search engines, these embeddings serve as the backbone of modern Arabic NLP applications.
Despite the complexities of Arabic—such as its rich morphology, diacritics, and dialectal variations—word embedding models like Word2Vec, GloVe, and FastText have laid a strong foundation. More advanced models, including AraVec and contextual embeddings like AraBERT, continue to push the boundaries of Arabic language understanding.